项目简介
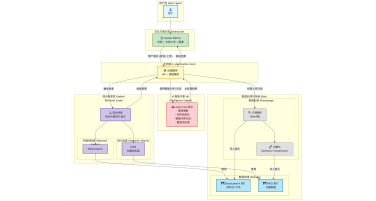
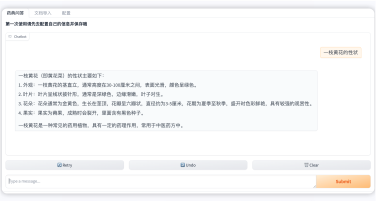
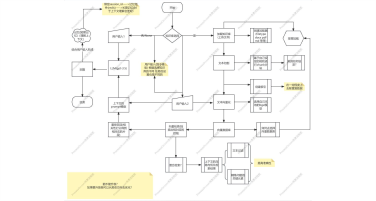
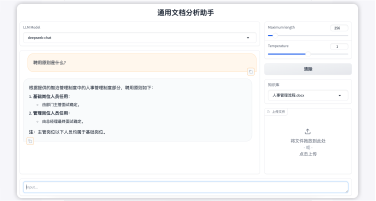
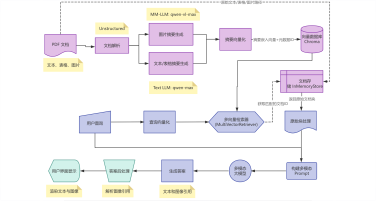
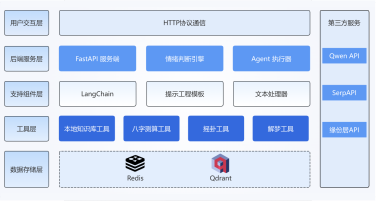
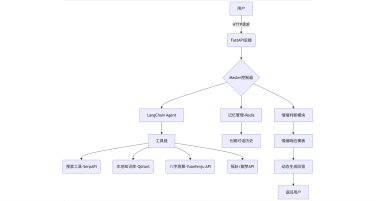
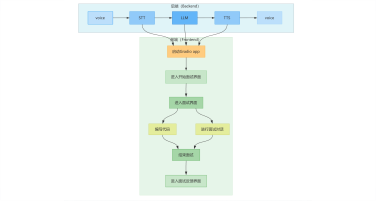
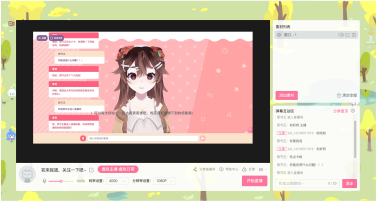
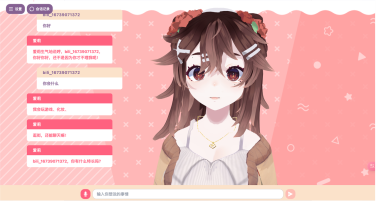
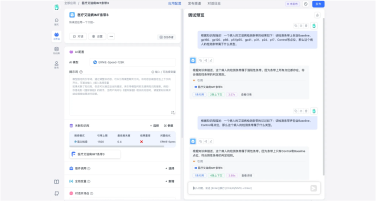
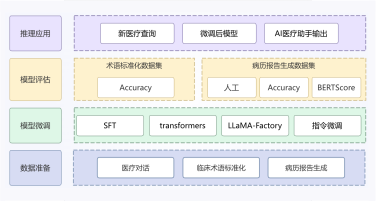
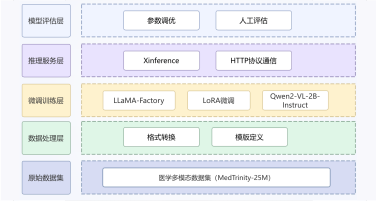
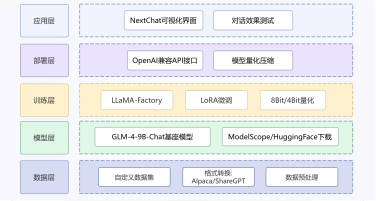
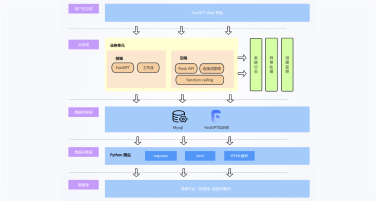
本项目旨在构建一个高效、智能的微博舆情分析系统,以应对社交媒体时代信息爆炸、舆情瞬息万变的挑战。该系统通过定制化的网络爬虫程序,实时爬取微博热搜榜单数据(包括标题、热度值等)以及对应热搜话题下的相关舆情数据(如用户评论、转发内容)。爬取的数据经过处理后,结构化信息被精准存入 MySQL 数据库,同时关键的舆情内容被构建成知识库。在此数据基础上,系统利用 FastGPT 平台搭建工作流 (Workflow)。该工作流能够基于用户输入的分析请求, 自动进行关键词提取,并通过 Function Calling 机制,智能调用预设函数来检索知识库中的语义信息,最终实现对特定热搜事件的快速、深度的舆情分析与洞察呈现。
FastGPT 微博舆情 舆情分析 网络爬虫 MySQL RAG
Function Calling 工作流
学习收获
1.掌握针对动态社交媒体平台(如微博)的实时网络爬虫技术与策略。
2.熟练运用MySQL进行结构化数据的存储、管理与高效查询。
3.理解并实践面向特定领域(舆情)的知识库构建方法,支撑语义检索与分析。
4.精通FastGPT平台,特别是其工作流设计与配置能力。
5.深入掌握Function
Calling机制在LLM应用中的核心作用,实现模型与外部数据源(数据库、知识库)的智能交互。
6.实践利用LLM进行关键词提取等自然语言处理预处理任务。
7.获得构建从数据采集、存储、处理到智能分析的端到端舆情监控与分析系统的实战经验。
8.了解如何将大语言模型应用于社会计算与舆情洞察领域。
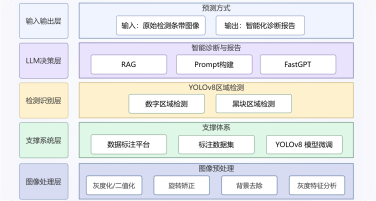
项目架构图
项目包含